


Grazia Antonacci, Implementation and Health Improvement Lead, Deputy Lead, Innovation and Evaluation, NIHR ARC Northwest London at Imperial College London, shared a post on LinkedIn:
“Is your clinical AI actually ready for the ward, or is it just ‘performing’ well on paper?
As we push the boundaries of Digital Health, the medical literature is flooded with predictive AI models designed to estimate disease probabilities.
Yet, a critical question remains: are we using the right yardsticks to measure their success?
A new Viewpoint in The Lancet Group Digital Health provides a much-needed reality check on how we evaluate AI intended for medical practice.
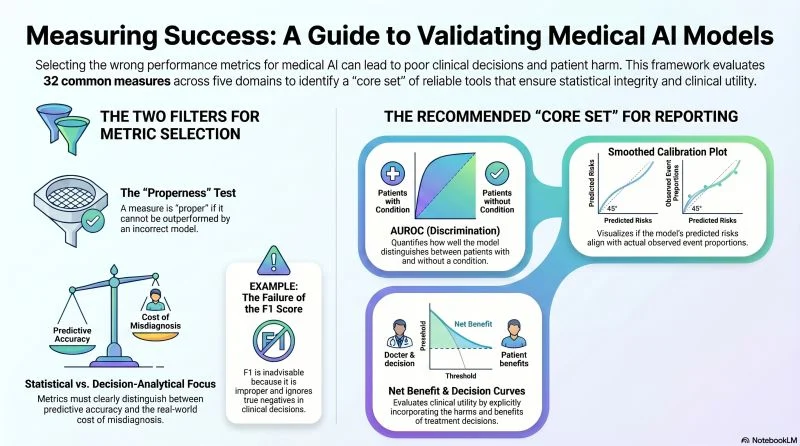
After assessing 32 performance measures across five domains-discrimination, calibration, overall performance, classification, and clinical utility-the experts have a clear message: not all metrics are created equal.
Here are three key takeaways for industry leaders, researchers, and clinicians:
- Beware of ‘Improper’ Measures:
- A performance measure is ‘proper’ only if its expected value is optimised when the model provides the correct probabilities. Shockingly, the study found that 13 out of 32 measures are improper, including the widely used F1 score, which fails to account for clinically relevant decision thresholds and conflates statistical performance with clinical utility.
- Statistical Performance ≠ Clinical Utility:
- While discrimination (AUROC) tells us if a model can distinguish between patients with and without a condition, it doesn’t tell us if using the model actually leads to better clinical decisions. We must prioritise Clinical Utility, specifically measures like Net Benefit, which explicitly incorporate the real-world costs of misclassification (false positives vs. false negatives).
- The ‘Core Set’ for Validation:
- To ensure AI models are safe and effective, the authors recommend reporting a specific core set of results:
-
-
- AUROC (Discrimination)
- Smoothed Calibration Plots (to see if predicted risks match observed outcomes)
- Net Benefit with Decision Curve Analysis (Clinical Utility)
- Probability Distribution Plots (to visualise model behaviour)
-
If we want digital health tools to move from ‘promising research’ to ‘standard of care’, we must stop relying on ambiguous, improper metrics and start focusing on true decision-analytical value.”
Title: Evaluation of performance measures in predictive artificial intelligence models to support medical decisions: overview and guidance
Authors: Ben Van Calster, Gary Collins, Andrew Vickers, Laure Wynants, Kathleen Kerr, Lasai Barreñada, Gael Varoquaux, Karandeep Singh, Karel Moons, Tina Hernandez-Boussard, Dirk Timmerman, David McLernon, Maarten van Smeden, Ewout Steyerberg

Other articles about Digital Health on OncoDaily.
{kind=link}