


Gustavo Monnerat, Deputy Editor at The Lancet, shared a post on LinkedIn:
“2 blinded clinicians. 6 AI systems. 100 real patient questions
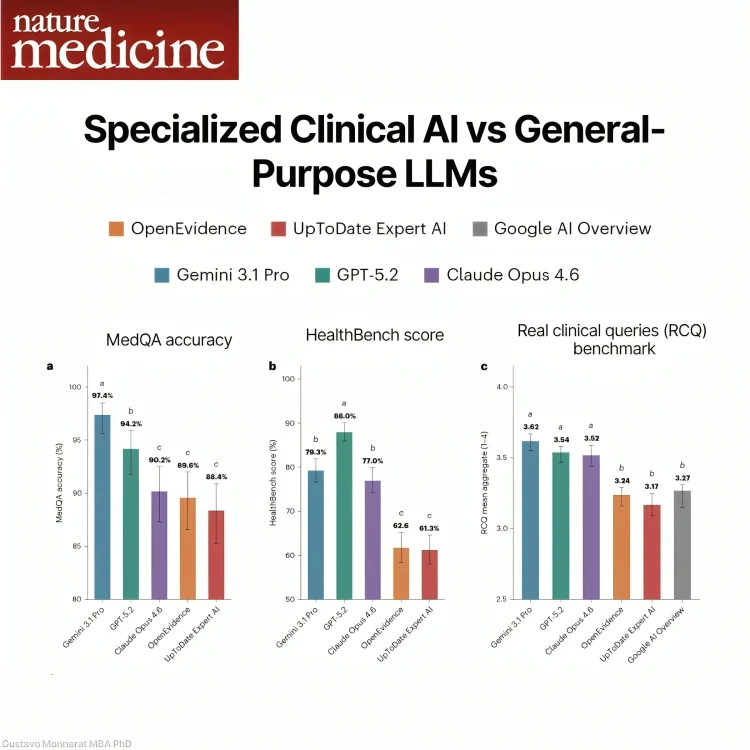
New in Nature Medicine: 3 frontier LLMs vs 2 specialized clinical AI tools, across two automated benchmarks plus 100 real clinical queries judged by 12 blinded clinicians. The frontier models came out ahead on all three.
Good news on safety: all six systems hallucinated at the same low rate.
Caveats: the headline gap comes from public exam questions the models may have trained on, and the clinical tools were tested through their browser, not API. Latency and citation quality weren’t assessed.
My take: relevant study, but a benchmark won’t always reflect real-world use. I’d expect frontier models to win some tasks and specialized tools others.
The open questions are the ones that interest me most:
- How do these tools perform with residency doctors versus experienced clinicians?
- Should we rely on models that can’t open the full text of clinical trials?
- How do they hold up across settings and countries with different patterns of epidemiology and disease burden?”
Title: General-purpose large language models outperform specialized clinical AI tools on medical benchmarks
Authors: Krithik Vishwanath, Anton Alyakin, Mrigayu Ghosh, Ali Hage, Sean N. Neifert, Cordelia Orillac, Nataniel J. Mandelberg, Hammad A. Khan, Jin Vivian Lee, Jie J. Yao, William Robert Small, Aakaash Varma, D. Brock Hewitt, Yindalon Aphinyanaphongs, Daniel Alexander Alber, Eric Karl Oermann
Read the article here.

Other articles featuring Gustavo Monnerat on OncoDaily.
{kind=link}